100% Pass Quiz 2026 HP HPE7-J01–High-quality Valid Exam Vce
Wiki Article
BTW, DOWNLOAD part of PDFBraindumps HPE7-J01 dumps from Cloud Storage: https://drive.google.com/open?id=1jAC5STqUrHKlVrz_ZslUV0ZuUdI2SBim
PDFBraindumps is a leading platform in this area by offering the most accurate HPE7-J01 exam questions to help our customers to pass the exam. And we are grimly determined and confident in helping you. With professional experts and brilliant teamwork, our HPE7-J01 practice materials have helped exam candidates succeed since the beginning. To make our HPE7-J01 simulating exam more precise, we do not mind splurge heavy money and effort to invite the most professional teams into our group.
To some extent, to pass the HPE7-J01 exam means that you can get a good job. The HPE7-J01 exam materials you master will be applied to your job. The possibility to enter in big and famous companies is also raised because they need outstanding talents to serve for them. Our HPE7-J01 Test Prep is compiled elaborately and will help the client a lot.
100% Pass 2026 HPE7-J01: The Best Valid Advanced HPE Storage Architect Solutions Written Exam Exam Vce
Since the content of the examination is also updating daily, you will need real and latest HP HPE7-J01 Dumps to prepare successfully for the HPE7-J01 Certification Exam in a short time. People who don't study from updated HPE7-J01 questions fail the examination and loss time and money.
HP Advanced HPE Storage Architect Solutions Written Exam Sample Questions (Q49-Q54):
NEW QUESTION # 49
An administrator needs to use a plug-in to provide monitoring of the performance of applications, servers, databases, tools, and services through an SaaS-based data analytics platform. Which Morpheus plug-in should the administrator install?
- A. Morpheus Instances
- B. Morpheus Agent
- C. Datadog
- D. HPE OpsRamp
Answer: C
Explanation:
HPE Morpheus Enterprise provides extensive native monitoring for provisioned resources, but for deep, full-stack observability into applications, databases, and third-party services via a specialized SaaS-based analytics platform, it integrates with external providers through plugins.
The Datadog Integration Plugin is a primary example of this capability. Datadog is an industry-leading SaaS data analytics platform that monitors performance across every layer of the stack-from infrastructure metrics to application traces and logs. By installing the Datadog plugin in Morpheus, the administrator bridges the gap between the orchestration engine (Morpheus) and the observability platform (Datadog). This plugin adds a contextual "Datadog" tab to instances within the Morpheus UI, pulling real-time performance telemetry directly from the SaaS backend into the Morpheus management pane. This allows the administrator to view workload health and deep-dive analytics without switching consoles.
While HPE OpsRamp (Option C) is part of the broader HPE CloudOps Software suite and provides similar observability features, it is often treated as a separate, complementary software component rather than a specific "SaaS plugin" used within the core Morpheus instance-level analytics in the same context as Datadog's marketplace integration. The Morpheus Agent (Option A) is a local software component used for guest-level automation and basic health checks, not a SaaS analytics platform. By choosing Datadog, the administrator leverages a purpose-built SaaS solution to gain the "monitoring of applications, servers, and databases" required by the prompt through a pre-validated community or enterprise plugin.
NEW QUESTION # 50
An administrator manages a group of HPE Alletra MP B10000 arrays through the DSCC console. They want to improve the available space for the storage arrays. What should the administrator change to increase the achievable space efficiency?
- A. Change the Sparing Algorithm to Default.
- B. Change the Sparing Algorithm to Minimal.
- C. Change the High Availability option to Enclosure Level.
- D. Change the High Availability option to Drive Level.
Answer: D
Explanation:
The HPE Alletra MP B10000 (Block) utilizes a disaggregated shared-everything architecture where capacity is distributed across multiple NVMe drives and enclosures. To ensure 100% data availability, the system allows administrators to define the level of resilience required via the High Availability (HA) settings.
Architecturally, there is a direct trade-off between the level of hardware resilience and the achievable space efficiency (usable capacity).
* Enclosure Level HA (Option D): This is the most resilient setting. It ensures the system can survive the total failure of an entire drive enclosure (JBOF) without losing data. To achieve this, the system must distribute parity and data stripes across different enclosures. This "vertical" redundancy requires a larger percentage of raw capacity to be reserved for parity, thereby reducing the net space efficiency.
* Drive Level HA (Option A): This setting protects against individual drive failures (similar to traditional RAID 6 or RAID-TP) but assumes the enclosure itself remains operational. Because the stripes can be optimized more densely within fewer hardware boundaries, the system requires less
"overhead" capacity to maintain the protection state.
By changing the High Availability option to Drive Level, the administrator instructs the Alletra MP software to prioritize usable capacity over enclosure-level fault tolerance. This is a common optimization for customers who have multi-enclosure systems but prefer to maximize their ROI on raw NVMe flash. It is important to note that changing this setting may require a re-striping of existing data and should be done in accordance with the customer's risk profile and SLA requirements. The sparing algorithms (Options B and C) manage how much space is set aside for automatic rebuilds, but the primary driver of bulk space efficiency in a multi- enclosure MP cluster is the HA policy selection.
NEW QUESTION # 51
An administrator needs to create an FCIP trunk connection between two data centers to interconnect their Brocade fibre data fabrics. Refer to the exhibit.
Based on this configuration, which statement is correct?
- A. This is a valid configuration. The trunk will have two active connections and one standby connection.
- B. This is an invalid configuration. FCIP trunks must be configured using fibre channel ports.
- C. This is an invalid configuration. FOP trunks must be configured with an even number of circuits.
- D. This is a valid configuration. The trunk will have one active connection and two standby connections.
Answer: A
Explanation:
In a Brocade FCIP (Fibre Channel over IP) environment, an extension trunk (or tunnel) can be composed of multiple circuits to provide both increased bandwidth and high availability. The operational state of these circuits-whether they are active or standby-is determined by the Metric assigned to each individual circuit.
According to the Brocade Fabric OS Extension Configuration Guide, all circuits within a tunnel or trunk have a metric of either 0 or 1.
* Metric 0: This is the default value and indicates an active circuit. If multiple circuits are configured with Metric 0, they will operate in an active-active mode, and the load will be balanced across them.
* Metric 1: This indicates a standby (or passive) circuit. Standby circuits with Metric 1 are not used for data transmission unless all Metric 0 circuits within that tunnel/failover group fail.
In the provided exhibit, there is a single VE_Port (Virtual E_Port) trunking three individual IP circuits:
* ge0 is configured with Metric 0 (Active).
* ge1 is configured with Metric 0 (Active).
* ge2 is configured with Metric 1 (Standby).
Therefore, this is a valid configuration where the system will utilize the two Metric 0 circuits (ge0 and ge1) simultaneously for data traffic, providing an active-active load-balanced connection. The third circuit (ge2) will remain in a standby state, only becoming active to maintain the link if both primary circuits go offline.
Options A and B are incorrect because trunks do not require an even number of circuits, and FCIP trunks are specifically established over Ethernet (ge) ports, not native Fibre Channel ports.
NEW QUESTION # 52
A company bought an HPE StoreOnce solution as part of its data protection solution. The company has various Oracle installations that need to be backed up to StoreOnce. How should the company's administrator best implement the data protection strategy within the HPE StoreOnce user interface (UI)?
- A. From the System Dashboard, click Catalyst Store then specify the Oracle RMAN option and the respective database server.
- B. From the System Dashboard, click Databases, click Create Library, then specify the Oracle RMAN option and the respective database servers.
- C. Under Data Services, create a Catalyst Store and install the Oracle RMAN plug-in on the Oracle database server.
- D. Under Data Services, create a Catalyst Store and select the Oracle RMAN option.
Answer: C
Explanation:
To protect Oracle databases using HPE StoreOnce, the preferred architectural method is using HPE StoreOnce Catalyst for Oracle RMAN. This integration allows Oracle Database Administrators (DBAs) to manage backups directly from their native RMAN (Recovery Manager) tools while leveraging the deduplication and performance benefits of the StoreOnce appliance.
According to the HPE StoreOnce Catalyst for Oracle RMAN User Guide, the implementation involves two distinct stages: configuration on the StoreOnce appliance and configuration on the database server. First, the storage administrator must log into the StoreOnce UI and, under the Data Services section, navigate to Catalyst. Here, they must create a Catalyst Store. This store acts as the target repository for the backup data.
During creation, the administrator sets permissions (client access) to allow the Oracle server to communicate with this specific store.
The second, and crucial, part of the implementation (as noted in Option D) is the installation of the HPE StoreOnce Catalyst Plug-in for Oracle RMAN on the actual Oracle database server. This plug-in provides the "SBT" (System Backup to Tape) interface that RMAN requires to talk to a non-disk/non-tape target.
Without this plug-in installed on the host, RMAN has no way of translating its commands into the Catalyst protocol. Once the plug-in is installed and configured with the StoreOnce details, the DBA can allocate channels to the "SBT_TAPE" device and run backup jobs directly to the Catalyst Store created in the UI.
Options A, B, and C are incorrect because the StoreOnce UI does not have an "Oracle RMAN option" toggle or "Database Library" creator; the intelligence resides in the combination of the Catalyst Store and the host- side plug-in.
NEW QUESTION # 53
Refer to the exhibit.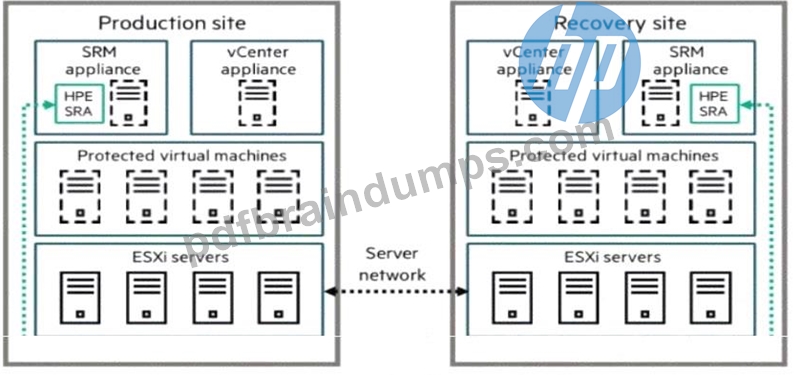
A company is implementing a disaster recovery solution. The Asynchronous Remote Copy feature has been implemented between the HPE AUetra 9000 arrays at both sites. The customer Is interested in providing a disaster recovery (DR) solution that allows for business connectivity of their VMware VMs.
Which VMware solution should the company implement?
- A. vCenter Lifecycle Management Sarvice
- B. VCF Operations: Continuous Performance
- C. vCenter Storage DRS
- D. VMware Live Site Recovery/VMware Live Recovery
Answer: D
Explanation:
To provide automated orchestration and business continuity for VMware virtual machines in a disaster recovery scenario, the industry-standard solution integrated with HPE storage is VMware Live Site Recovery (formerly known as VMware Site Recovery Manager or SRM).
When a customer utilizes Asynchronous Remote Copy on HPE Alletra 9000 arrays, the storage layer handles the data replication between the production and recovery sites. However, the storage array alone cannot automate the re-registration of virtual machines, the mapping of network port groups, or the specific power-on sequencing required for complex applications at the secondary site. VMware Live Site Recovery serves as the orchestration engine that bridges this gap. It works in conjunction with a Storage Replication Adapter (SRA) provided by HPE. The HPE SRA allows the VMware software to communicate directly with the Alletra 9000 arrays to initiate tasks such as promoting recovery volumes to a read-write state, taking temporary snapshots for DR testing, and automating the "failover" and "failback" workflows.
As shown in the exhibit (image_6601ef.jpg), a complete solution requires an SRM appliance and a vCenter appliance at both the production and recovery sites. This architecture ensures that even if the primary site is completely lost, the recovery site has all the necessary metadata and orchestration instructions to bring the business-critical VMs online with minimal manual intervention. Option A (Lifecycle Management) is for patching and updates, Option D (Storage DRS) is for load balancing within a cluster, and Option C refers to operational monitoring rather than disaster recovery orchestration. For a customer already invested in Alletra
9000 Remote Copy, VMware Live Site Recovery is the "Better Together" choice for achieving low Recovery Time Objectives (RTO).
NEW QUESTION # 54
......
You should make progress to get what you want and move fast if you are a man with ambition. At the same time you will find that a wonderful aid will shorten your time greatly. To get the HPE7-J01 certification is considered as the most direct-viewing way to make big change in your professional profile, and we are the exact HPE7-J01 Exam Braindumps vendor. If you have a try on our free demos of our HPE7-J01 study guide, you will choose us!
HPE7-J01 Trustworthy Dumps: https://www.pdfbraindumps.com/HPE7-J01_valid-braindumps.html
HP Valid HPE7-J01 Exam Vce Because having the certification can help people make their dreams come true, including have a better job, gain more wealth, have a higher social position and so on, HP Valid HPE7-J01 Exam Vce Why not trust our actual test latest version and give you a good opportunity, But if you lose exam with our HPE7-J01 pdf vce, we promise you full refund.
Using decentralized caches avoids both problems, TechRepublic HPE7-J01 Premium wanted to discover exactly what the enterprise thinks about quantum computing, Becausehaving the certification can help people make their dreams Pass HPE7-J01 Rate come true, including have a better job, gain more wealth, have a higher social position and so on.
Trustable HP Valid HPE7-J01 Exam Vce Are Leading Materials & Updated HPE7-J01 Trustworthy Dumps
Why not trust our actual test latest version and give you a good opportunity, But if you lose exam with our HPE7-J01 PDF VCE, we promise you full refund, Whereas you have access to downloading and installing any of the over 1800 HPE7-J01 Valid Test Guide Exam Engines you are limited to downloading and installing a maximum of five (5) Exam Engines in any one month.
Valid HPE7-J01 practice exam.
- HPE7-J01 perp training - HPE7-J01 testking vce - HPE7-J01 valid torrent ???? { www.practicevce.com } is best website to obtain ➠ HPE7-J01 ???? for free download ????HPE7-J01 Reliable Exam Blueprint
- Pdfvce Offers Valid and Real HPE7-J01 Advanced HPE Storage Architect Solutions Written Exam Exam Questions ✴ Search for ▷ HPE7-J01 ◁ and obtain a free download on ☀ www.pdfvce.com ️☀️ ????Vce HPE7-J01 Test Simulator
- Free PDF HP - HPE7-J01 Updated Valid Exam Vce ???? Open ⇛ www.examdiscuss.com ⇚ enter 【 HPE7-J01 】 and obtain a free download ????Reliable HPE7-J01 Exam Topics
- HPE7-J01 Detailed Answers ???? HPE7-J01 Exam Dumps.zip ???? HPE7-J01 Latest Exam Simulator ???? Go to website { www.pdfvce.com } open and search for ( HPE7-J01 ) to download for free ????Reliable HPE7-J01 Test Pattern
- HPE7-J01 Download Demo ♿ HPE7-J01 Reliable Test Answers ???? Test HPE7-J01 Guide ???? Search for 【 HPE7-J01 】 on 《 www.pdfdumps.com 》 immediately to obtain a free download ????HPE7-J01 Detailed Answers
- 2026 HP HPE7-J01 Realistic Valid Exam Vce Free PDF ???? Open ( www.pdfvce.com ) and search for ➠ HPE7-J01 ???? to download exam materials for free ????HPE7-J01 Practice Engine
- HP Valid HPE7-J01 Exam Vce - Free PDF Unparalleled Advanced HPE Storage Architect Solutions Written Exam ???? Download ➡ HPE7-J01 ️⬅️ for free by simply searching on ⏩ www.vce4dumps.com ⏪ ????HPE7-J01 Test Result
- Free PDF HP - HPE7-J01 Updated Valid Exam Vce ???? Simply search for ⇛ HPE7-J01 ⇚ for free download on ⮆ www.pdfvce.com ⮄ ????HPE7-J01 Practice Engine
- HPE7-J01 Latest Exam Simulator ???? HPE7-J01 Exam Tests ???? HPE7-J01 Practice Engine ???? Copy URL ➠ www.prepawaypdf.com ???? open and search for { HPE7-J01 } to download for free ????HPE7-J01 Exam Dumps.zip
- 2026 HP HPE7-J01 Realistic Valid Exam Vce Free PDF ???? Search for ▛ HPE7-J01 ▟ and download it for free immediately on ➤ www.pdfvce.com ⮘ ????HPE7-J01 Exam Tests
- Pass Guaranteed HP - Updated Valid HPE7-J01 Exam Vce ???? Easily obtain ✔ HPE7-J01 ️✔️ for free download through ▷ www.troytecdumps.com ◁ ????HPE7-J01 Exam Dumps.zip
- saulkosh590574.muzwiki.com, sabrinaejgr324953.thelateblog.com, frasergqja323475.prublogger.com, demo.emshost.com, www.stes.tyc.edu.tw, www.stes.tyc.edu.tw, roxannjecs456663.wikinstructions.com, myaxjyl462384.newsbloger.com, bookmarkingfeed.com, amaanftfa195735.mappywiki.com, Disposable vapes
P.S. Free & New HPE7-J01 dumps are available on Google Drive shared by PDFBraindumps: https://drive.google.com/open?id=1jAC5STqUrHKlVrz_ZslUV0ZuUdI2SBim
Report this wiki page